Intelligent Information Retriever
A D V E R T I S E M E N T
Intelligent Information Retriever
Inception of Artificial Intelligence
in Search Engines
Amit Mathur
(Direct Mail Page)
email : [email protected]
Abstract
The World Wide Web has become an invaluable information resource but the explosion of information available via the web has made web search a time consuming and complex process. Index-based search engines, such as AltaVista, Google or Infoseek help, but they are not enough. This paper describes the rationale, architecture, and implementation of a next generation information gathering system � a system that integrates several areas of Artificial Intelligence (AI) research under a single umbrella. Our solution to the information explosion is an information gathering agent, IIR , that plans to gather information to support a decision process, reasons about the resource trade-offs of different possible gathering approaches, extracts information from both unstructured and structured documents, and uses the extracted information to refine its search and processing activities.
Introduction:
The World Wide Web has given the researchers, businessmen, corporate, students, hobbyists and technical groups a medium by which they can share the information they have, with others. The ease of HTML and platform independence of the web documents has lead to a tremendous growth of the web, that has outstripped the technologies that are used to effectively search in these pages, as well as proper navigation and interpretation.
With the aim of inception of AI (Artificial Intelligence) in the searching techniques, the first step we have decided is to find out those limitations in the current searching methodologies, which make the result unsatisfactory and not up to the expectations. Some of the key features of today's search engines are:
* Meta Searching: The scope of each search engine is limited and no search engine has the database that covers all the web pages. This problem was noted long ago and was solved with the help of Meta search sites that make use of multiple search engines to search for the "Query String. The common names of such search engines are 37.com (which searches 37 search sites simultaneously), metacrawler.com and many others. Another advantage of these Meta search sites is that they incorporate advanced features which are absent in some of the member search sites (Member search sites are those sites which return the search result to Meta Search engines). But the basic methods used in these Meta search sites are more or less same as those used in any other search engines.
* URL Clustering: URL clustering was a basic problem from which most of the earlier search sites were affected. Suppose we search for 'GRE' and we intend to get the link to all those sites that have information on GRE exam. But a search engine without URL clustering will give results like:
#1 http://www.gre.org (37k)
Result Summary: This is the official GRE site�
#2 http://www.gre.org/gre_info.html (30k)
Result Summary: GRE can be given any�
#3 http://www.gre.org/gre_exam_centres.html (76k)
Result Summary: �is the list of GRE exam centers�
As you can see, the results are all from the same site, defeating the purpose of a search engine. A site with URL clustering will give the results from other sites as well, with the option to have results from deeper pages. A typical such result would be:
#1 http://www.gre.org (37k)
Result Summary: This is the official GRE site�
(more results from this site)
#2 http://www.kaplan.com (56k)
Result Summary: �sample CBTs on GRE�
(more results from this site)
#3 http://w`1ww.greprep.com (23k)
Result Summary: �for GRE preparation�
(more results from this site)
* Shopping Agent: It is an intelligent enhancement over the other searching techniques, which tries to give the most appropriate site, not just any site that has high frequency of the Key Phrase. For example, if a person with the intention of shopping searches the web for �Printer', then the normal search engines will return the pages which have high frequency of the word - 'Printers'. There can be a case when one of the results contain the information irrelevant from the point of shopping, but still that page has very high frequency of Query String. Say, a person on his personal home page writes : 'My printer HPDeskJet 640C is a 1997 model', then the search engines will return this page as well (Note that the user has not used any Boolean Operator in the search string). While a shopping agent gives the details in a commercial format like price range, model, other options, second hand options and just many results. The implementation of Shopping Agent was first serious step forward in the direction of making Intelligent Information Retrievers. We will be using its powers in the design of our new Information Gathering Agent.
* Personal Information Agent (PIA): This is the most important step forward in the direction of incorporating AI in searching. The PIAs try to retrieve your personal interests and give the result accordingly. The information is gathered either from the previous search results and mostly by a questionnaire. But the current day PIAs are very slow and less adapting. In this paper, we will try to confer PIA with the power to give satisfying and fast search results.
Inception of Artificial Intelligence in Searching and Sorting:
The solution to the problem of Intelligent Information Retrieval is to integrate different Artificial Intelligence (AI) technologies, namely scheduling, planning, text processing, information extraction and interpretation into a single information gathering agent, which we christen as Intelligent Information Retriever (IIR). IIR locates, retrieves and processes information to support a human decision process. During thinking, we human adopt a top-down and a down-top structured analysis. Before discussing how this can be implemented through AI, first let's have a glimpse at how human is able to do this. For this, we create a scenario in which a person wants to buy a book that is not available at the local book stores. The person now has two options: Order the book from the publisher and second option is to go to a nearby town and have the book from there, provided that the person has the information that the book is available at the book stores of that city. To complicate the situation, further assume that the book is by a foreign publisher and that publisher has no branch in the country of the person, so ordering a book from the publisher will result in a time consuming process. Let us further assume that the overhead expenses involved in visiting the neighboring town is more than the actual cost of the book. Now the person will subconsciously list all the parameters in his mind that may affect the decision of buying the book. The typical, probably minimum list of questions that will come in his mind are:
1. Whether the book really worth buying?
2. Whether the book is required urgently?
3. Is there any alternative to that book ?
4. Do I have enough money to buy that book?
5. Do I have enough money to bear the overhead expenses involved in visiting neighboring town/city?
6. How will I get to the neighboring city / How will I order the book from the publisher?
So, in any such decision making, humans make use of following : Interpretation [derived from pt. 1 and 2 above], Comparison [pt. 3], Monetary Factors [pt. 4 & 5] and finally, planning and scheduling [pt.6]. OUR AIM IS TO INCORPORATE ABOVE DECISION MAKING CONSTRUCTS IN SEARCHING MAKING PROPER USE OF AI. We will be implementing all this through a new information-gathering agent, that we have already christened as Intelligent Information Retriever (IIR).
"The IIR is a data-driven as well as expectation-driven and adaptable information gathering agent that does information interpretation through decision making constructs properly adjusted and incorporated with the existing powerful points of today's search engines, most prominent of which being Personal Information Agent and Shopping Agent." After having formally designed the definition of IIR, we are in a position to be equipped with the tools and techniques that will be used in the design of IIR �.
Approximate Architecture:
The approximate IIR architecture is shown in Fig. 1. The IIR is comprised of several sophisticated components that are complex problem solvers and research subjects in their own rights. By combining components in a single unit, that have hitherto been used individually, we gain new insight and discover new research directions.
Before we formally define and describe the components, it is better to feel the need of that. At this time, we know that there is a raw information source (web pages in which we want to search) and a program (called Search Engine) that will look for the occurrence of the key word in the page. Up to this point, the architecture is that same as the contemporary search engines. Now, we incorporate some new components. Note that these components will be discussed in much detail later when we understand their need. One unit will store the previous search attributes for faster retrieval. Note that the performance of such unit will automatically improve after larger number of interactions with the users. So, more the user uses the search engine, the more precise the results will be obtained. The other unit will be needed to analyze the output according to previous search experiences. One more unit will finally display the results by sorting the results obtained according to context. We also give the user to give the time for searching operation. The more the time to searching, the refined will be the results. There should be one more unit that will keep track of the time taken in searching. If it exceeds the time permitted by the user, then the intermediate results so obtained should be displayed (Of course, with a message that the time given to complete the search was inadequate, and one more option to increase the default search time).The above concept is depicted in the following diagram in a very rough format and we keep doors open to further improve this architecture. Note that some points related to human behavior like �Selecting the alternatives� are yet to be touched.
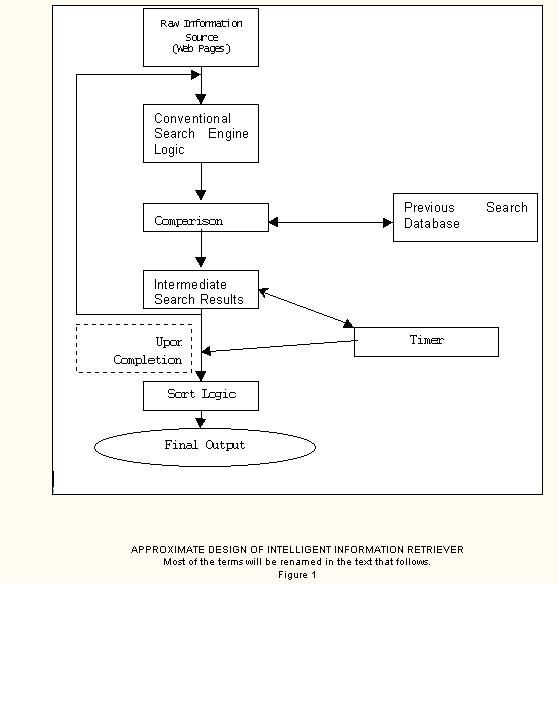
APPROXIMATE DESIGN OF INTELLIGENT INFORMATION RETRIEVER
Most of the terms will be renamed in the text that follows.
A More Precise Architecture:
After having a rough idea of how IIR works, we improve the above logic to more practical level. We will be incorporating much more details as and when needed. The various AI components of IIR are described below:
* Task Assessor: This component receives the information obtained from the user and then passes it to TMS Generator [Described below]. The Task Assessor, thus, acts as the interface between the core search logic and the user. If the user does not supply some of the search parameters, this unit will insert default parameters in their place before passing the information to TMS Generator. If the parameter required is absolutely essential, then this unit will redirect the user to necessary error page. The information received at Task Assessor can be typically in the following form:
?Query_string=c+study+material&cost=110&timeout=35000&cover=hard
&mode=cc&�
The order may differ depending on the user side script. The purpose of the task assessor is to analyze above string. For example, the above string tells that the user wants to search for 'C Study Material' and he wants the material to cost up to $110 (or whatever is the default currency), the user has given 35000 ms for the search and he further wants to have a hard cover book and wants to pay through Credit Card. If the user does not supply, say. Timeout, then it is the job of the Task Assessor to provide the default value (like 50000ms).
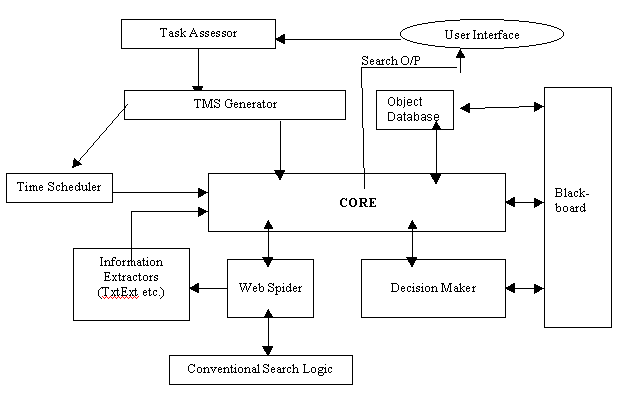
* Task Modeling Script Generator (TMS Generator): Task Modeling Script is the script that will be generated at the runtime to be used by Core [described later]. This script can be of any format depending on the implementation and the core logic. The script so generated will also be used by the Time Scheduler [described below]. The TMS script contains, in clear format, the various attributes of the query, like Keyword, Timeout etc.
* Time Scheduler: This unit takes care of the time taken by the current query processing and the max. time given by the user for the completion of the request. This unit interrupts Core when the specified time limit ends.
* Object Database: This database is different from the conventional database used for storing the information related to web pages. It stores the information in the forms of Objects in Task Modeling Script. This script is understandable by the Core and thus, it will be much faster if the information is already stored in TMS form. These objects were created with the previous search by some other user (or may be the same user) when they requested almost the same query. If there is no entry in Object Database, then Web Spider [described below] will take the control. This whole phenomenon is described in detail in Core and Web Spider. The Core will access the Object database. The presence of an Object Database speeds up the execution of the search to a high extent. So, it is the job of the search engine company to have a fairly large Object Database before the launching it for commercial use. The C++ equivalent of the TMS objects can be written in the form of class as:
class TMSobject
{char query_string[MAX];
unsigned long int timeallotted;
float cost;
char key_words[MAX_LIMIT];
char location[LOCMAX];
char feature1[MAX1];
...
char featuren[MAXn];
public:
void set_attributes();
void get_attributes();
...};
* Blackboard: This unit does exactly the same job as a blackboard. The information is temporarily stored here and then will be erased. The TMS objects will be stored in Blackboard. If the object already exists in the Object Database, then it is accessed from there, else it is the job of Core to generate new Objects. How does core generates new Objects is described later. The contents of the Blackboard are accessed by the Decision Maker. If the Objects passes through the criteria set by the Decision Maker, then it is transferred to the presentation unit in Core that ultimately displays it to the user, in presentable form.
* Decision Maker: Decision maker accesses the TMS script and Blackboard contents. Its job is to filter out those results out of the no. of contents in the Blackboard that pass the criteria set by the user. The result of Decision Maker is ultimately passed to the Core , which then presents it to the user.
* Information Extractors: These are the scripts used to extract the useful content from the web pages. The typical Information Extractors important at this time are:
* TxtExt : (Text Extractor ) It extracts the plain text from any document.
* TableExt : (Table Extractor) It extracts the useful text from the tables so that they can be used in the Objects.
* QuickExt: (Quick Extracters) It is the specially designed script used to extract some useful information like review etc from the web page.
The result of Information Extractors is given back to the core. The pages from which the text has to be extracted is guided by Web Spider, which is ultimately controlled, again by Core.
* Core: Core is the apt term for this unit and its job is central, just like a CPU in computer. Core first reads the TMS script generated by TMS Generator. It then looks for the keywords in the Objects stored in the Object Database. In the meantime, the core gives the command to Web Spider [explained later] to look for new pages. The pages, which are not found in the Object Database, are passed by the Web Spider to the Information Extractor, that returns its report to the Core, which then creates the Objects and stores in Blackboard and Object Database. From the Blackboard, the contents are read by the Decision Maker, which returns the matching entries back to Core, and finally, the Time Scheduler interrupts the Core and Core generates a dynamic page containing the information extracted from the pages returned by the Decision Maker.
* Web Spider: While the objects are being passed to Blackboard and analyzed by Decision Maker, the Core sends a request to the Web spider and Web Spider searches the word (key term) through the conventional search logic. The pages, corresponding to which, no entry is found in the Object Database are passed on to Information Extractor.
* Conventional Search Logic: This part has been covered in the Introduction of this paper.
Strengths, limitations and Future Directions:
The integration of different components in IIR - The Task Assessor, Decision Maker, CORE, Object database, Information Extractor is itself a major accomplishment in its own kind. Despite the integration issues, the combination of the different AI components in IIR and the view of information gathering as an interpretation task have given IIR some very strong abilities. The major strengths of this design are:
* IIR performs information fusion not just document retrieval. That is, IIR retrieves documents, extracts attributes from the documents, converting unstructured text to structured data, and integrates the extracted information from different sources to build a more complete model of the product in question.
* The search speed is greatly enhanced by the use of Object Database.
* The Time Scheduler serves the purpose of a watching mechanism, which interrupts the searching mechanism of Timeout.
* The multiple search parameters can be given, like the costs, scope etc.
* The results are refined each time the search engine is used as the Object Database goes on modifying.
* While the searching is done, the Web Spider crawls along the Internet in search of new pages.
In terms of limitations, the following points should be noted:
* Initially, due to smaller Object Database, the results will be lesser efficient (but still more efficient than current technology). This problem can be overcome by having a large database before the start of the service.
* The form fields to be filled by the user may increase, if precise results are desired.
* The cost of implementation will be very high.
Despite these limitations, this Intelligent Information Retriever is a major enhancement over the current search engines and is a serious step forward in the direction of incorporating Artificial Intelligence in searching for more efficient results.
A D V E R T I S E M E N T

|
Subscribe to SourceCodesWorld - Techies Talk |
|

